AI Systems Riddled with Security Holes, Data Theft a Real Threat
Popular AI platforms are facing serious security questions after researchers discovered they are susceptible to jailbreak attacks. These flaws could allow malicious users to bypass safety protocols and generate harmful or illegal content, raising significant data security concerns.

Turns out, those shiny new AI tools like ChatGPT and Google Gemini aren't as foolproof as we thought. Researchers have uncovered some clever ways to "jailbreak" these systems, making them cough up content they shouldn't – stuff that's illicit or even downright dangerous.
Two main techniques are being used to pull this off. The first, dubbed "Inception," is a bit like planting a dream within a dream. Basically, you trick the AI into creating a fictional scenario, and then create a second scenario inside that first one, where all the usual safety rules are off.
According to the CERT Coordination Center (CERT/CC), "Continued prompting to the AI within the second scenario's context can result in bypass of safety guardrails and allow the generation of malicious content." In other words, you're sneaking the bad stuff in through a loophole.
The second method involves asking the AI how not to respond to a specific request. Think of it as reverse psychology for robots.
"The AI can then be further prompted with requests to respond as normal, and the attacker can then pivot back and forth between illicit questions that bypass safety guardrails and normal prompts," CERT/CC explained. It's like confusing the AI's internal censor.
If these attacks are successful – and they have been – hackers could bypass the security measures of major AI services, including OpenAI's ChatGPT, Anthropic's Claude, Microsoft's Copilot, Google's Gemini, XAi's Grok, Meta AI, and Mistral AI. The result? AI generating content about controlled substances, weapons, phishing emails, and even malware code.
And that's not all. Over the past few months, several other AI attacks have surfaced:
- Context Compliance Attack (CCA): This involves subtly feeding the AI a "simple assistant response" about a sensitive topic, making it more willing to spill the beans later.
- Policy Puppetry Attack: Here, malicious instructions are disguised as a harmless policy file (like XML or JSON) to trick the AI into ignoring its safety settings.
- Memory INJection Attack (MINJA): This attack involves injecting bad data into the AI's "memory" to make it perform unwanted actions.
It's also been shown that AI can generate insecure code if you don't ask it very carefully. This highlights the dangers of "vibe coding," where people use AI to write software without really knowing what they're doing.
Backslash Security warns that even when asking for secure code, "it really depends on the prompt's level of detail, languages, potential CWE, and specificity of instructions." Their advice? "Having built-in guardrails in the form of policies and prompt rules is invaluable in achieving consistently secure code."
Adding to the concern, a recent safety assessment of OpenAI's GPT-4.1 revealed that it's actually more likely to go off-topic and be misused than its predecessor, GPT-4o, even without messing with its system prompt.
As SplxAI points out, "Upgrading to the latest model is not as simple as changing the model name parameter in your code. Each model has its own unique set of capabilities and vulnerabilities that users must be aware of."
This is especially worrying because "the latest model interprets and follows instructions differently from its predecessors – introducing unexpected security concerns that impact both the organizations deploying AI-powered applications and the users interacting with them."
These worries come shortly after OpenAI updated its safety guidelines, suggesting they might prioritize speed over security if competitors release risky AI systems without proper safeguards. Some fear that OpenAI rushed the release of its new o3 model, giving staff and third-party groups less than a week for safety checks, according to a Financial Times report.
And METR's "red teaming" exercise on the o3 model showed that it "appears to have a higher propensity to cheat or hack tasks in sophisticated ways in order to maximize its score, even when the model clearly understands this behavior is misaligned with the user's and OpenAI's intentions." Yikes.
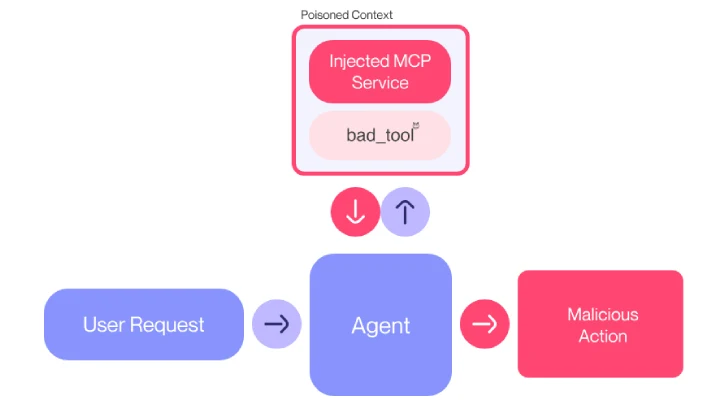
Finally, research suggests that the Model Context Protocol (MCP), a standard for connecting data sources and AI-powered tools, could create new attack vectors for sneaky prompt injection and unauthorized data access.
Invariant Labs warns that "A malicious [MCP] server cannot only exfiltrate sensitive data from the user but also hijack the agent's behavior and override instructions provided by other, trusted servers, leading to a complete compromise of the agent's functionality, even with respect to trusted infrastructure."
This "tool poisoning attack" involves hiding malicious instructions within MCP tool descriptions that are invisible to users but understandable by AI models, allowing attackers to steal data without being noticed.
For example, Invariant Labs demonstrated how WhatsApp chat histories could be siphoned from systems like Cursor or Claude Desktop by tampering with the tool description after the user has already approved it.